
|
|
SUMP Pump™ Programming
Introduction
Even as chip manufacturers steadily increase the number of processor cores per CPU, writing multiprocessor software remains difficult. Solid state storage speeds are doubling each year, currently providing file access rates of more than a gigabyte per second. How can programmers rapidly develop programs that utilize both multiple cores and the new storage transfer rates? SUMP (Scale Up MultiProcessor) Pump™ is a program and subroutine library that allows programmers to quickly write programs to use multiple CMP/SMP processors and process file data at gigabyte-per-second speeds.
SUMP Pump is similar to Google's MapReduce and Hadoop MapReduce software frameworks in that it automatically replicates either programmer-defined functions or programs across multiple processors. With Google's MapReduce or Hadoop, multiple streams of input data are read in parallel across a cluster, processed in parallel using replicated functions or programs, and the multiple output streams are then written in parallel. But with SUMP Pump, an input stream is sequentially read into a process and dynamically divided into separate input partions, each of which is processed by a programmer-defined function or external program thereby producing a sequence of output segements that are concatenated to produce a single output stream.
While Google and Hadoop MapReduce facilitate scale-out parallelism, SUMP Pump facilitates scale-up parallelism. SUMP Pump's sequential input and output streams provide the following features of speed and modularity:
- high-speed processing of the input and output streams that can utilize solid state storage.
- within an application program utilizing the SUMP Pump library, easy connecting of SUMP Pump instances with either multithreaded Nsort instances or application program threads.
- with the sump program, easy connections via pipes with either the multithreaded Nsort or other programs.
SUMP Pump can be used to process MapReduce programming models, but it's modular design allows it to be used in much simpler programs. In fact it is expected the majority of programs utilizing SUMP Pump will not involve MapReduce-type processing.
Overview
A stream of data entering a sump pump is processed in parallel using either:
- an external program that reads its standard input and writes its standard output
- a programmer-defined pump function that reads input data and writes output data to one or more output streams.
The external program or pump function is invoked in parallel by a pool of process threads that are automatically created and managed by the sump pump infrastructure. An external program can produce a single output stream, while a pump function can produce one or more output streams. Those output streams are automatically concatenated to form one or more combined output streams from the sump pump.
The sump pump input stream can come from any of the following:
- A file, including standard input.
- The output stream of another sump pump.
- A series of sp_write_input() calls from another thread.
The output stream from a sump pump can be directed to any of the following:
- A file, including standard output.
- The input stream of another sump pump.
- A series of sp_read_output() calls from another thread.
The sump pump input/output processing possibilities include the full cross product of the above options. A sump pump can be used to process in parallel the output of a program before it is written to an output file (thread input, file output). Conversely it can be used to process program input being read from an input file (file input, thread output).
The sump pump infrastructure handles synchronization between sump pump threads, and with external threads that are invoking sp_write_input() or sp_read_output(). By freeing the programmer of this burden, multithreaded programs can be developed more quickly and reliably.
There are three types of pump functions:
- Whole-buffer
- Map
- Reduce
Whole-buffer pump functions obtain an input buffer pointer and buffer size in order to read their input. Map and reduce functions read a record at a time to process their input. The records can either be a fixed number of bytes, or a sequence of ascii characters terminated by a newline. The input records for a map function do not necessarily have a common attribute. The input records for a reduce function may share a common attribute, such as a common key value. An extra byte or character must have been added to each input record to help the reduce sump pump determine which records share the same attribute. A reduce sump pump will insure that all records with a shared attribute, and only those records, are processed by the same pump function invocation. This record group encoding can be produced the Nsort parallel subroutine library.
A map sump pump and a reduce sump pump can be combined with an invocation of the Nsort parallel subroutine library to create an SMP/CMP implementation of the MapReduce functionality popularized by Google. Google's MapReduce distributes the processing of Map and Reduce methods across multiple nodes in a cluster, and handles disk and node failures. But sump pump only distributes the processing of Map and Reduce operators across multiple threads in a single process, and leaves the issue of disk redundancy to the i/o subsystem. For an example of MapReduce functionality, see the Billing programming example below.
If the pump function record processing is not context-sensitive then no matter how many sump pump threads are used the sump pump processing is stable (to borrow a term from the field of sorting) - that is the ordering of the input records in the input stream is preserved in the ordering of the processed versions of the input records in the output stream.
Simulation
A simulation of whole-buffer sump pump is presented below. There are start/pause and reset controls, and way to slow down a variable number of sump pump threads.
For an explanation of the above sump pump simulation, please see below a labeled still image of the simulation with label explanations.
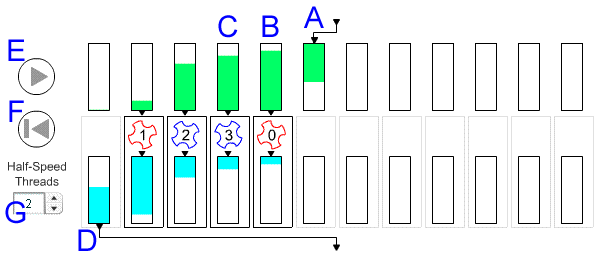
A. Data is being written into the sump pump by an outside thread calling the sp_write_input() function. This function copies the input data to a nonempty input buffer. The input buffers are represented by the top row of rectangles. In the still image the input data is being written into the input buffer 5 (the 12 input buffers are numbered 0 - 11 from left to right). The task input buffers are filled sequentially in a circular pattern to maintain the order of the input data.
B. There are also 12 sump pump tasks represented by the bottom row of large rectangles. Task 4 is being executed by the sump pump's thread number 0, as represented by the 0 inside the gear. Task execution consists of executing either an external process or a programmer-defined pump function that reads and processes the task's input in an input buffer, and writes its output to the task's output buffer (represented by the smaller rectangle inside the task rectangle).
There are 4 sump pump threads in the simulation. By default the sump pump system will create one thread for each processor in the system. The threads execute tasks in a serial fashion. The number of the thread executing the task is indicated by the number inside the spinning gear. The simulation allows for full-speed or half-speed threads. A red spinning gear indicates execution by a full-speed thread. A blue gear indicates task execution by a half-speed thread. Because some processors in the system may be busy executing other jobs or programs, some sump pump threads may not be able to process sump pump tasks at the same rate as other threads.
C. Task 3 is being executed by thread 3, which is a half-speed thread as indicated by the blue gear.
D. The output buffer of task 0 is being read by an outside thread calling the sp_read_output() function. Note that the task output buffers are drained sequentially in a circular fashion. Along with the in-order filling of input buffers, this maintains overall order in the data processing.
E. The Pause/Play control allows the simulation to be paused and resumed.
F. The Restart button allows the simulation to be restarted.
G. The number of half speed threads can be adjusted here. The simulation default is 0 and may be increased to include all 4 threads. In an actual system, threads may slow down due to preemption by the operating system. If all processors in the system are available, the operating system should assign each of the sump pump threads to one of the available processor cores. In a busy system, the sump pump threads may be allotted varying amounts of processor time by the operating system, but on average that time should not differ by more than a factor of 2. Try adjusting the number of half-speed threads in the simulation to see how the sump pump still keeps the faster threads busy processing tasks instead of degrading to the speed of the slowest thread.
Program Examples and Performance Results
Six example programs and their performance results are given below. The programs demonstrate various ways in which SUMP Pump can be used, mixing various types of SUMP Pump input streams and output streams. The Billing and Word Count examples use MapReduce type processing, whereas the other four examples only use a single sump pump. The Word Count example uses the sump program, whereas all other examples are written as programs that host the sump pump library.
For each example, the input and output data sets fit in main memory so that performance is not limited by the speed of an input/output device or file system. These example programs and the scripts to run them are included in the sump pump source distribution.
A table of performance results is shown for each example listing the number of logical processors used, the elapsed time in seconds, total user cpu time, total system cpu time, and the average i/o rate (number of bytes read and written divided by the elapsed time). The tests were done on a Linux system with a single Intel® Core™ i7-980X processor with 6 cores and 12 hyperthreads. Performance results are given for 1, 2, 3, 6 and 12 logical processors. Since using 12 processors on this machine requires the use of hyperthreaded processors, that processor count is labelled 12H to remind the reader of this fact. Hyperthreaded processors do offer performance benefits, but can also cause either cache or memory access contention as evidenced by the rise in total user cpu time.
For the program examples that achieve high in-memory i/o rates, test results are also given for larger data sets that do not fit in main memory. For these cases the file storage is provided on an ext4 file system on an xlv-striped device consisting of 4 Intel X25-M solid state drives connected by an Intel RS2BL080 controller.
Each program example contains a data flow diagram that shows how the data flows through the program and any input or output files. The data always flows from the top of the diagram to the bottom. Graphical symbols used in the flow diagrams are as follows:
|
| Process | |
|
| File Data Transfer | |
|
| Inter-Process Pipe | |
|
| Intra-Process Data Flow to/from a SUMP Pump |
Lookup
The lookup program is roughly similar to the Unix join program except that it uses hash look ups internally and does not require either of its inputs to be sorted. It also assumes that one of its inputs contains unique key values and will fit in main memory. The lookup program also demonstrates the use of a sump pump with two output streams, one for records with a matching key and the other records without a match.
| Input File | ||
| ||
| Match File | Nomatch File | |
| Processors | Elapsed | User | System | IO MB/sec |
|---|---|---|---|---|
| 1 | 11.07 | 10.51 | 0.56 | 170.5 |
| 2 | 6.14 | 11.43 | 0.63 | 307.3 |
| 3 | 4.34 | 11.76 | 0.80 | 434.8 |
| 6 | 2.45 | 12.72 | 0.90 | 770.2 |
| 12H | 1.79 | 18.32 | 1.06 | 1054.2 |
| Processors | Elapsed | User | System | IO MB/sec |
|---|---|---|---|---|
| 12H | 108.4 | 493. | 8.4 | 557. |
How It Works
There are two file inputs, lookupin.txt and lookupref.txt, both of which contain comma-separated values. The first field in each file is a key value. The lookupref.txt file contains reference records with unique key values and is assumed to fit in main memory. In the performance example, lookupref.txt contains 1,017,396 records and 10,805,540 bytes. The lookup program builds a hash table from the records in lookupref.txt. The lookupin.txt input file (20,000,000 records, 913,363,767 bytes) is read into a sump pump. For each input record, the pump function looks up the record's key in the hashed reference table. If the key is found the remaining (non-key) fields of the reference record are appended to the end of the input record and written to a pump function output that goes to the output file match.txt. If no matching key is found, the input record is written to an alternate pump function output that goes to the output file nomatch.txt.
For example, assume the reference file contains:
apple,sauce
mango,pulp
The input file contains:
lemon,012,345,678
mango,987,654,321
apple,555,555,555
berry,222,222,222
apple,888,888,888
Then the match.txt output file will contain:
mango,987,654,321,pulp
apple,555,555,555,sauce
apple,888,888,888,sauce
And the nomatch.txt output file will contain:
lemon,012,345,678
berry,222,222,222
Pump Function Code Show
Billing
The billing program reads a log of telephone exchange call detail records and produces phone bills. The program uses two sump pumps and the multithreaded Nsort library in a way that is functionally similar to the MapReduce mechanism for processing data on a cluster, except that in the sump pump implementation the map function input is read from a single file and the reduce function output is written to a single file. The following diagram shows the data flow.
| Input File | |||||
| |||||
| Output File | |||||
| Processors | Elapsed | User | System | IO MB/sec |
|---|---|---|---|---|
| 1 | 21.32 | 20.81 | 0.49 | 48.8 |
| 2 | 11.09 | 21.33 | 0.57 | 93.9 |
| 3 | 7.64 | 21.80 | 0.63 | 136.3 |
| 6 | 4.18 | 22.93 | 0.70 | 249.0 |
| 12H | 3.33 | 34.09 | 0.99 | 312.6 |
How It Works
The billing program reads a file of phone call records, billing_input.txt, and writes a series of phone bills to billing_output.txt.
The file billing_input.txt contains 10,001,830 call detail records with fields for the originating phone number, destination phone number, date/time, minutes of call duration, and an unnecessary field. These records are synthetically generated and are an abbreviated format of actual call detail records:
...
6502075186,1738108607,2010:01:15:04:44:00,8,10000274
6502879128,2760604299,2010:01:19:21:55:00,23,10000275
6502612994,2977419483,2010:01:08:18:26:00,28,1000032
6502245279,8483380882,2010:01:01:17:24:00,9,10000328
...
These records are sent through a map pump function, map_pump(), that performs the trivial, 1:1 record transformation of dropping the unnecessary field at the end of the record. (Note that more complex transformations, e.g. 1:many or 1:0, are also possible during the map pump function.) The records then look like:
...
6502075186,1738108607,2010:01:15:04:44:00,8
6502879128,2760604299,2010:01:19:21:55:00,23
6502612994,2977419483,2010:01:08:18:26:00,28
6502245279,8483380882,2010:01:01:17:24:00,9
...
The records are sorted by the Nsort subroutine library using the originating phone number as the first key, and the date/time as the second key. The sort output logically looks like the following, although there is additional information (not shown) to help the subsequent sump pump group together records by key value:
...
6502000001,6122014655,2010:01:16:12:18:00,11
6502000002,6045401969,2010:01:01:00:44:00,11
6502000002,3527948477,2010:01:02:05:57:00,11
6502000002,4232810775,2010:01:03:22:38:00,19
6502000002,4492155117,2010:01:04:09:39:00,1
6502000002,4009615215,2010:01:05:05:38:00,12
6502000003,4729657570,2010:01:01:09:42:00,13
...
The Nsort output feeds to a reduce sump pump: a sump pump that has been initiated with a GROUP_BY directive to insure that all records with equal keys (just the originating phone number in this case) end up in the same pump function input. The reduce pump function, reduce_pump(), reads all the records for each originating phone number and produces a "phone bill" for that originating number. For example, the bill for the records for 6502000002 shown above would be:
(650)200-0002
(604)540-1969 Jan 1 00:44 11
(352)794-8477 Jan 2 05:57 11
(423)281-0775 Jan 3 22:38 19
(449)215-5117 Jan 4 09:39 1
(400)961-5215 Jan 5 05:38 12
Total minutes 54
Average minutes 10
Minimum 1
Maximum 19
Map Pump Function Code Show
Reduce Pump Function Code Show
Word Count
Word Count is a common MapReduce programming example that counts the instances of unique words in a document. Whereas the previous MapReduce example, Lookup, was implemented as a single process with two internal sump pumps and one nsort subroutine library instance, the Word Count example uses two sump program processes and one nsort process. It demonstrates how the same mapper and reducer programs designed for use with Hadoop streaming on a network can also be used with the sump and nsort programs on a single-node system. In the example, a mapper python script is called repeatedly and in parallel by one instance of the sump program. The output of this sump program is piped to an instance of the nsort program whose output is piped to another sump program instance that invokes the reducer.py script in parallel. Note that the external programs invoked by the sump program are not limited to Python, and can be written in any language. For more information on how to use the exact same python scripts to perform a word count on Amazon Web Services, see this O'Reilly video.
Word Count is a very compute-intensive application, owing to the small intermediate records and interpreted language processing. This accounts for its much lower achieved IO rates.
| Input Document | |
| |
| |
| |
| Word Count Output File | |
| Processors | Elapsed | User | System | IO MB/sec |
|---|---|---|---|---|
| 1 | 34.78 | 33.87 | 0.74 | 3.1 |
| 2 | 17.66 | 33.92 | 0.76 | 6.1 |
| 3 | 12.03 | 34.02 | 0.79 | 9.0 |
| 6 | 6.53 | 34.03 | 0.86 | 16.5 |
| 12H | 6.08 | 56.67 | 1.28 | 17.8 |
How It Works
This Word Count example uses two instances of the sump program, and one instance of the Nsort program. The first sump program reads an approximately 100 MB input file and calls a Python script, mapper.py, repeatedly and in parallel, to extract words from the lines of the input file. The output of this first sump program consists of, for each word found in the input file, a line of text containing the word, a tab character and the digit 1. For instance if the word found was aardvark, the following line of text would be emitted:
aardvark\t1\n
The sump program output is piped to an instance of the nsort program. Nsort is directed to treat each input line as a record with a word field and a count field. The records are sorted by the word field. In addition, when nsort encounters two records with identical words, it may delete one of the records and add the count value of the deleted record to the surviving record. This process is known as a summarization and is supported by many commercial sort programs.
The output of nsort is piped to a second sump program instance that calls a Python script, reducer.py, repeatedly and in parallel. The python script reads the word/count pairs and produces a simple line of output as follows:
aardvark was found 2 times
For performance testing the two instances of the sump program and the nsort instance are invoked using a shell script, available below.
Shell Script Show
Mapper.py Code Show
Reducer.py Code Show
Gensort
The Gensort program generates a data file that can be used as an input file for a set of sort benchmarks. The pump functions in this example perform 1:N transformations, turning one 1 generation instruction into N records. The program illustrates: 1) how the output of a single program thread can be processed in parallel by a sump pump and then written to an output file; and 2) how a sump pump can be used as a general task queuing mechanism.
| |||
| Sort Input Records File | |||
| Processors | Elapsed | User | System | IO MB/sec |
|---|---|---|---|---|
| 1 | 7.44 | 7.12 | 0.32 | 134.4 |
| 2 | 3.75 | 7.09 | 0.36 | 266.7 |
| 3 | 2.58 | 7.12 | 0.40 | 387.6 |
| 6 | 1.31 | 7.10 | 0.37 | 763.4 |
| 12H | 0.92 | 9.50 | 0.43 | 1087.0 |
| Processors | Elapsed | User | System | IO MB/sec |
|---|---|---|---|---|
| 12H | 80. | 384. | 5.6 | 625. |
How It Works
The main thread writes a series of instruction structures to the sump pump. The structure contains a starting record number and the number of 100-byte records to generate:
struct gen_instruct
{
u16 starting_rec; /* starting record number */
u8 num_recs; /* the number of records to generate */
};
The sump pump is configured so that each pump function instance will read just one instruction structure, and generate the specified number of records starting with the specified record number.
Pump Function Code Show
Valsort
The Valsort program validates the correct sorted order of records in a file and computes a record checksum. Like Gensort, it is used by a set of sort benchmarks. The pump function for valsort performs an N:1 transformation, reducing the records in its input to a resulting structure. This is effectively a reduction by input buffer, rather than a reduction by key value. Valsort also illustrates more generally how a sump pump can be used to process an input file in parallel while the main program thread reads that processed input.
| Sorted Records File | |||
| |||
| Processors | Elapsed | User | System | IO MB/sec |
|---|---|---|---|---|
| 1 | 1.91 | 1.69 | 0.22 | 523.6 |
| 2 | 1.22 | 2.15 | 0.27 | 819.7 |
| 3 | 0.91 | 2.38 | 0.30 | 1098.9 |
| 6 | 0.58 | 2.72 | 0.35 | 1724.1 |
| 12H | 0.46 | 3.45 | 0.46 | 2173.9 |
| Processors | Elapsed | User | System | IO MB/sec |
|---|---|---|---|---|
| 12H | 46. | 167. | 5.9 | 1087. |
How It Works
The input of the sump pump is a file whose records will be checked for having the correct sort order and checksum. Each pump function performs a many:1 transformation, reading all the records in its input buffer and reducing them to the following summary structure. The structure contains the index of the first unordered record in the input buffer (if any), number of unordered records, number of records, number of duplicate-keyed records, checksum of the records, and the first and last records in for the input buffer.
struct summary
{
u16 first_unordered; /* index of first unordered record,
* or 0 if no unordered records */
u16 unordered_count; /* total number of unordered records */
u16 rec_count; /* total number of records */
u16 dup_count; /* total number of duplicate keys */
u16 checksum; /* checksum of all records */
char first_rec[REC_SIZE]; /* first record */
char last_rec[REC_SIZE]; /* last record */
};
Pump Function Code Show
The main thread reads the summary structures from the chain gang output. It verifies the last record of a summary structure is correctly ordered relative to the first record of the next summary structure, and keeps running totals of the number of unordered records, number of records, unique keys, and the record checksums. This work is trivial compared to the CPU use of the chain gang threads, so the program scales well.
Spgzip
Spgzip demonstrates the relative simplicity of using sump pump to develop a highly scalable gzip-compatible compression program with the aid of the zlib library. Spgzip is simply a demonstation program whose functionality is limited compared to pigz - a general purpose, multiprocessor, gzip-compatible compression program. In spite of its simplicity, Spgzip provides comparable performance to pigz when compressing the same input file used in this performance test. The output of pigz was 0.3% smaller than spgzip's, but pigz used approximately 3% more elapsed time.
| Uncompressed Input File | |
| |
| Compressed Output File | |
| Processors | Elapsed | User | System | IO MB/sec |
|---|---|---|---|---|
| 1 | 21.12 | 20.90 | 0.24 | 19.6 |
| 2 | 10.58 | 20.83 | 0.25 | 39.1 |
| 3 | 7.08 | 20.80 | 0.22 | 58.5 |
| 6 | 3.58 | 20.88 | 0.30 | 115.6 |
| 12H | 2.76 | 32.11 | 0.33 | 150.0 |
How It Works
The pump function simply passes pointers to its input buffer and output buffer to zlib routines which do the compression. The sump pump infrastructure concatenates the output buffers. For this benchmark, gzip compresses a 274,747,890 byte file.
Pump Function Code Show
Downloading
SUMP Pump is downloadable as a GNU GPL v.2 project on the Google Code website. It currently runs only on x86 or x64, Linux or Windows systems. The project code includes SUMP Pump, the performance programs listed on this page, regression test programs, makefile, and Python scripts for running the performance and regression tests.
If you want to try out the Nsort executable and library with SUMP Pump, you can get an Nsort for Linux or Windows trial from here. There is a free (gratis), text-only license available for Nsort on Linux (only). Follow the above trial link. First select a Linux version (x86 or x64), then select the free, gratis download.
FAQ
What types of records are supported?
Currently, just ascii (UTF-8) lines of text and fixed-size records.
What types of records are supported for sorting and reducing?
Currently, just ascii (UTF-8) lines of text.
Why is it that SUMP Pump's interfaces just support records and not key/data pairs like with Google's MapReduce?
For now, the assumption is that the key is part of the record and can be identified as such to the sort. A key/data interface will be developed later.
Can any type of stream processing be sped up by SUMP Pump?
There has to be some amount of non-trivial CPU processing for SUMP Pump to speed up processing.
What happens if a task output buffer fills up, is this a fatal condition?
If a task output buffer fills up such that the thread executing the pump function cannot continue, it is not a fatal condition but some parallel execution may be lost. The thread must wait until the output buffer is read. The output buffer can then be filled with the subsequent output of the pump function. Ideally, when this happens the sump pump infrastructure should automatically allocate an additional output buffer and decrease the ratio of the input buffer sizes to the output buffer sizes.
If a reduce pump function is used, the input records must be grouped by key values. So how are these groups of input records laid out in the input buffers?
As with whole-buffer or map pump functions, the input buffers are always completely filled with records. The SUMP Pump infrastructure will make repeated calls to a reduce pump function until all record groups in the input buffer have been processed. If a record group extends to the subsequent input buffer, then this is all handled invisibly by the infrastructure. The input buffer of each input record to the reduce pump function is not determinable. All a reduce pump function needs to do is get its input records one at a time until the infrastructure indicates there are no further records in the key group.
Which is better parallelism, Google's MapReduce or SUMP Pump?
It may seem that the two types of parallelism are polar opposites, but they are actually orthogonal. For instance, there is no reason why MapReduce can't be used for inter-node parallelism on a cluster, while SUMP Pump is used for some or all intra-node parallelism. The answer to the question depends mainly on the platform. SUMP Pump is tool to help programmers harness multiple processors on a single system, and to take advantage of the high-speed access rates offered by solid state storage. If that is the kind of system you are optimizing for, give SUMP Pump a look.
How does SUMP Pump differ from other single-node MapReduce implementations such as Phoenix or Mars?
SUMP Pump is modularized so it can be used for more than just MapReduce type processing. Moreover, by using Nsort for MapReduce processing, SUMP Pump can process data sets that do not fit in main memory.
How can I get additional functionality built into SUMP Pump?
You can do it yourself, or contract with Ordinal or someone else to add the functionality.
Is there a programming guide available?
The best currently available documentation for the SUMP Pump library is in the well-commented sump.h file. The sump program, if invoked with no arguments, will print out a summary of its command line options.
What licensing is required?
SUMP Pump is released under GPL v.2. You can distribute SUMP Pump with your code as long as you follow the terms of that license. If you want to use Nsort with your SUMP Pump program, you will need a license for Nsort. However, there will soon be a free (gratis) but functionally-limited and capacity-limited version of Nsort available for Linux platforms.